This is in addition to the terrible human cost, of course.
I’ve been told my whole life that “people vote with their pocketbooks.” Trump was elected, in a large part, because poorly-informed and intellectually lazy voters thought he might help the economy.
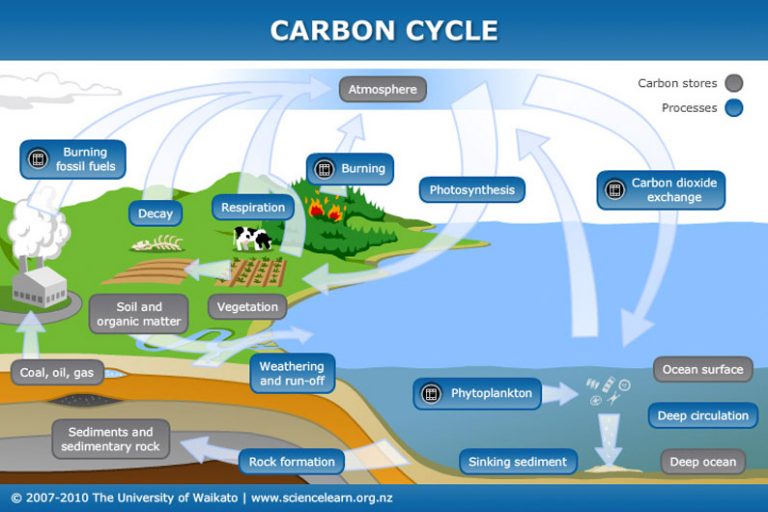
Carbon is fundamental. There’s no life (as we know it) without carbon’s ability to make covalent bonds with other atoms like hydrogen (H), nitrogen (N), oxygen (O), phosphorus (P), and sulfur (S). Take a look at the chemical formulae for the twenty essential amino acids that humans require and you’ll see a lot of C, H, O, with some N and an occasional S. Take a look at DNA and you’ll get plenty of P.
In college there are chemistry courses devoted entirely to carbon. They are called “organic” chemistry! That’s because all organic (that is, living or once-living) materials contain carbon. The classes have little to do with “organic” food and whatnot. Carbon makes such a byzantine variety of chemical combinations that an entire corpus of systematic nomenclature is devoted to these things. You don’t just learn about biological applications in organic chemistry, you learn about petroleum and its derivatives (plastics) as well. Fossil fuels are just that—fossils of once-living creatures. Oil is a mostly marine phenomenon, the source animals are plankton and algae, not Chevron’s dinosaurs. The gasoline we burn is from quite ancient places. The carbon atoms we liberate could have been there for 100 million years or more.
There is really only one thing to know about carbon, and that’s the carbon cycle. The earth is a vast repository of fossil carbon and we release lots of that fossil carbon because we are an industrial society. This of course has consequences. But carbon and its compounds like carbon dioxide cycle through every aspect of our existence even if we be Stone Age farmers. Carbon is life.
If you find something ancient, beautiful, and valuable on your land, what do you do? Do you extract it and turn it into dollars? Do you husband it for the future? Do you try to find a balance? That is, do you use the resource wisely? Do you think about externalities like clean air and water, quality of life, natural beauty, etc.? Is “value” in a capitalist economy only in terms of money?
The base elevation there is 5500 feet and the Grey Butte chair will take you up to 7536 feet. The park sits on the southern flank of massive Mt Shasta which tops out at 14,179 feet.
The other local ski resort—Mt Ashland, just over the Oregon border—has it a little better:
Those folks sit a little higher: it’s 6634 feet at the base and it’s 7533 feet on the summit (the top of Ariel chair). Mt Ashland is the tallest of the Siskiyou range and the resort sits on the peak’s north face.
I’m not complaining because I’m a frustrated skier. The conditions are certainly lousy for winter recreation. No, I’m complaining because this is not good. It’s not good for California. It’s not good for Oregon. It’s not good for anyone in the West.
In the West we depend on snowpack. Rain is great, sure. We love us some rain.
But it’s all about the snow. It’s got to accumulate. We need to come out of winter with all of our mountains blanketed in the stuff.
So far that’s not happening. And this patchwork of storms is not just alarming, it’s downright dangerous. The existing snowpack, under these warm, wet conditions is particularly unstable.
I don’t like hot, smoky summers. I don’t like watching the West burn. We need some goddamn snow!
The Stupor Bowl encourages us to be indifferent to the contest and watch the advertisements instead. This is backwards from my normal sports viewing—I always use the ad breaks for refills, trips to the loo, etc. I also like to get up and move around and not be a couch potato. So I don’t watch the famous adverts and in fact make a point to avoid them. This fits with my “hygiene” theme!
When I was a kid people were always saying that “too much TV is bad for you.” They were right.
Consciousness is a very precious realm. It’s the realm of our privacy and our freedom to think. So I think we need some kind of consciousness hygiene, particularly at this moment, where this one politician has figured out ways to command our attention.
Yes.
I’m all for consciousness hygiene! They used to say “tune in and turn on” but now I think we have to say “tune out and turn off.”
Every element after Uranium on the periodic table, that is, the ones that have a larger atomic number than 92, are created in the laboratory. They are not naturally occurring, unless you count things like debris from supernovas or nuclear explosions. Guys like Ernest O. Lawrence (he of Lawrence Livermore National Laboratory, Lawrence Berkeley Laboratory, and Lawrence Hall of Science fame) was one of the folks responsible for this “trans-uranic” stuff. If you bombard some elements with neutrons, or smash some nuclei together, you can get new elements. There are eleven transuranic elements (#93-103) in the actinide series that make up the lowest row of the table, and fifteen more (the “superheavies” from #104-118) filling out the bottom right of the main group.
So uranium is the last of the natural order of things. It’s the biggest and the baddest of all the natural elements. It has the most protons (92), the most electrons (92), and the most neutrons (146). The listed atomic weight for uranium is 238, the highest of the natural elements. Plutonium is the most massive at 244, but it is number 94.
A cubic inch block of pure uranium weighs about two-thirds of a pound.* It’s very dense stuff and so-called “depleted” uranium is used in armor-piercing shells (tank and anti-tank weapons) by the US Army. Depleted uranium is the stuff leftover from “enrichment” which separates the desirable U-235 isotope from the more abundant U-238. You need U-235 for fission reactors.
Speaking of that, our TechBro Overlords are making nuclear power fashionable again. They want to use nukes to power their precious data centers. These people are assholes who want to fuck up the world for the rest of us. Their puppet Donald is relaxing the safety rules on nuclear power stations so these very rich and very powerful people can have lots and lots and lots more electricity.
Hey, I don’t have an issue with nuclear power. We need it. But we need it done properly. And we need national oversight of the industry and strict safety and environmental laws. But that’s a joke with these people and their Republican lackeys.
And we certainly don’t need these fucking data centers and the AI crap they are shoving down our throats. It’s too bad that new tech like AI, which certainly has many wonderful applications, will be ruined by the greed, mendacity, just plain old creepiness of our celebrity capitalists.
Back to that cubic inch block of uranium. According to these nuke guys, a kilogram of uranium can generate 24 million kilowatt-hours of heat energy and thus 45,000 kW-h of electricity. So our piece comes in at 30% of that or about 13,500 kW-h. Compare that to coal where one kilogram creates a mere EIGHT kilowatt-hours of heat energy. Uranium is THREE MILLION times more energy-rich!! That’s six orders of magnitude.
Now do you see why people keep coming back to uranium and nuclear power?
As we watch the demented fascist who calls himself our president become even more unhinged and desperate, it’s hard not to despair of our country’s future.
But then, good things happen.
The workers from ILWU Local 34 (San Francisco) paid tribute to goon squad murder victim Renee Good with some clever stacking of containers:
We often forget that our wealth and comfort is built on the backs, sweat, and blood of ordinary workers. Without unions these people would be marginalized and forgotten. And even workers who are sometimes organized—like in the agriculture sector—the gains are small and the public interest negligible so the problems persist. We sing the praises of our capitalist system but without human bodies to exploit and abuse that system collapses. No one gets rich on their own, despite what our CEOs and techbros want you to believe. Workers of the world, unite! You’ve nothing left to lose.
Trump and the Republicans are OK with gunning down people in the streets. Thankfully lots of regular Americans feel differently.
Jeff Vandermeer’s trilogy (Area X) dealt with big themes like “what is real?” and “can their be more than one reality?” It also looked at human institutions like government agencies and research laboratories and how these things can morph from their original purposes.
Dan Chaon’s One of Us takes a more personal view. The story is set in a traveling carnival. This is a ripe area for fiction. On my bookshelf are Freakshow by Jacquin Sanders (1954), The Dreaming Jewels by Theodore Sturgeon (1950), and William Lindsay Gresham’s 1946 Nightmare Alley, made into two films (1947 and 2021) of the same name.
Stories about carnivals, circuses, and freakshows present us with outcasts—people on the margins of society. One of Us follows the misfortunes of a brother and sister who are orphaned young and then beset upon by a vicious relative. They are “rescued” by the carnival and their journey of self-discovery begins.
Chaon looks at the nature of relationships and their power dynamics. And he clearly has a soft spot for marginalized communities. What after all, makes us human? The characters in One of Us are too weird, too ugly, too bizarre, and too misshapen to have a chance in the regular world. And some of them have abilities that would terrify the “normies” and thus they have to be excluded from society.
The answer for them, of course, is to form their own society. Is this the answer for anyone who doesn’t “fit in?”
I certainly hope not. As nurturing as the carnival world is to its inhabitants, ultimately we all need to belong, and exclusion is not a recipe for a healthy civilization. Perhaps we outsiders, someday, will learn to see the beauty, uniqueness, and humanity of those in the closeted worlds we keep at arm’s length.
Minnesota is not a foreign country. It is not enemy soil. It is the United States of America. Our crazed, fascist president and his army of bloodthirsty sycophants are terrorizing and brutalizing citizens and residents. They have now executed two people for the crimes of disagreeing and speaking out.
Trump is a criminal. Stephen Miller, Kristi Noem, Greg Bovino, Kash Patel, and the rest are criminal co-conspirators. Our country is run by completely corrupt and thoroughly amoral assholes.
Enough is enough. Abolish ICE. Clean out the leadership and the goon squads in the CBP. This deadly assault on American freedoms is not “border patrol” or “immigration enforcement.” It is a racist crackdown on marginal communities and their supporters, and a deadly political reprisal against the president’s perceived enemies. And, in the end, a bloodletting. That’s what all these ICE/CBP actions are about. Trump and his lickspittles really, really, really want to crack heads. They want to cause pain and suffering. They get off on violence and, at this point, they don’t care who receives their rage.
People who support this shit should take a good look in the mirror.
These books walk the lines between horror, fantasy, and sci-fi. Sometimes people try the terms “speculative fiction” or “slipstream” for novels that aren’t genre-specific. Whatever. I think we should drop all those categories. Case in point: the Area X trilogy.
The books have a dystopian-SF surface layer. Beneath that is a Lovecraftian horror tale. Things get creepier as you go, and the sense of dread is palpable. Without giving things away, they get back to high-falutin’ SF with some stuff about time and dimensions and . . .
. . . a whole lotta other stuff. I found it mesmerizing.






{kind=link}